System and method for video context-based composition and compression from normalized spatial resolution objects
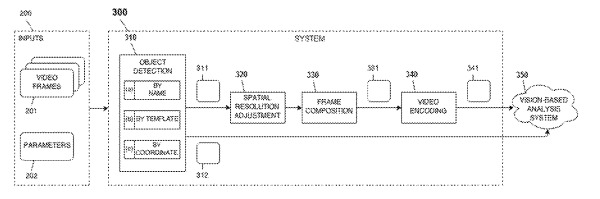
The present invention relates to a system and method for efficiently generating images and videos as an array of objects of interest (e.g., faces and hands, plates, etc.) in a desired resolution to perform vision tasks, such as face recognition, facial expression analysis, detection of hand gestures, among others. The composition of such images and videos takes into account the similarity of objects in the same category to encode them more effectively, providing savings in terms of time transmission and storage. Transmission time is less advantage to such a system in terms of efficiency, while less low cost storage means for storing data.
Type