Transmitting What Matters: Task-Oriented Video Composition and Compression
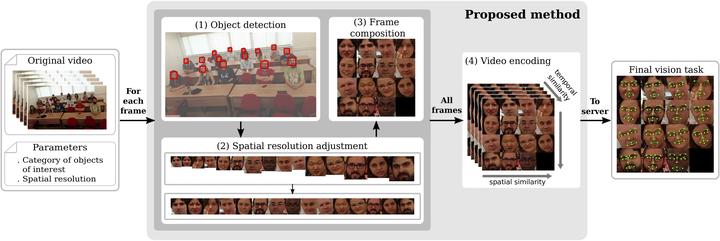
We present a simple yet effective framework - Transmitting What Matters (TWM) - to generate compressed videos containing only relevant objects targeted to specific computer vision tasks, such as faces for the task of face expression recognition, license plates for the task of optical character recognition, among others. TWM takes advantage of the final desired computer vision task to compose video frames only with the necessary data. The video frames are compressed and can be stored or transmitted to powerful servers where extensive and time-consuming tasks can be performed. We experimentally present the trade-offs between distortion and bitrate for a wide range of compression levels, and the impact generated by compression artifacts on the accuracy of the desired vision task. We show that, for one selected computer vision task, it is possible to dramatically reduce the amount of required data to be stored or transmitted, without compromising accuracy.