Exploring adaptation methods for small language models in domain-specific code generation
Aug 1, 2026· ,·
0 min read
,·
0 min read
Luís Freire
Fernanda Andaló
Nicki S. Detlefsen
Abstract
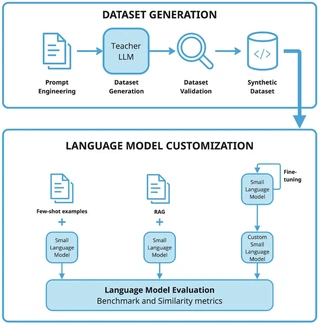
Large language models have shown strong capabilities in code generation, but adapting them to specialized domains remains challenging in settings with limited computational resources and scarce training data. Smaller open-source models provide an alternative to large proprietary systems, while synthetic data generation offers a scalable approach when curated datasets are unavailable. In this work, we investigate adaptation methods for small language models in domain-specific code generation using synthetic programming datasets. We construct datasets across three Python domains—general Python programming, Scikit-learn workflows, and OpenCV-based computer vision tasks—and compare few-shot prompting, retrieval-augmented generation (RAG), and parameter-efficient fine-tuning with Low-Rank Adaptation (LoRA). Experiments show that prompting-based methods improve domain alignment with limited overhead, but provide inconsistent gains in correctness, whereas LoRA-based fine-tuning achieves more reliable specialization across domains and evaluation metrics. Our findings highlight the role of synthetic supervision and the trade-offs between lightweight adaptation techniques when specializing small language models to domain-specific programming tasks in limited-resource settings.
Type
Publication
International Workshop on Generalizing from Limited Resources in the Open World, International Joint Conference on Artificial Intelligence (GLOW/IJCAI)